CVC4's native language
Contents
CVC4 native input language
The native input language consists of a sequence of symbol declarations and commands, each followed by a semicolon (;).
Any text after the first occurrence of a percent character and to the end of the current line is a comment:
%%% This is a native language comment
Type System
CVC4's type system includes a set of built-in types which can be expanded with additional user-defined types.
The type system consists of first-order types, subtypes of first-order types, and higher-order types, all of which are interpreted as sets. For convenience, we will sometimes identify below the interpretation of a type with the type itself.
First-order types consist of basic types and structured types. The basic types are 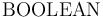 ,
, 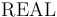 ,
, 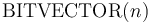 for all
for all 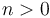 , as well as user-defined basic types (also called uninterpreted types).
The structured types are array, tuple, record types, and ML-style user-defined (inductive) datatypes.
, as well as user-defined basic types (also called uninterpreted types).
The structured types are array, tuple, record types, and ML-style user-defined (inductive) datatypes.
Note: Currently, subtypes consist only of the built-in subtype 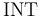 of .
Support for CVC3-style user-defined subtypes will be added in a later release.
of .
Support for CVC3-style user-defined subtypes will be added in a later release.
Function types are the only higher-order types. More precisely, they are just second-order types since function symbols in CVC4, both built-in and user-defined, can take as argument or return only values of a first-order type.
Basic Types
The BOOLEAN Type
The type is interpreted as the two-element set of Boolean values
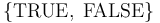 .
.
Note: CVC4's treatment of this type differs from CVC3's where is used only as the type of formulas, but not as value type. CVC3 follows the two-tiered structure of classical first-order logic
which distinguishes between formulas and terms, and allows terms to occur in formulas but not vice versa (with the exception of the IF-THEN-ELSE construct).
CVC4 drops the distinction between terms and formulas and defines the latter just as terms of type . As such, formulas can occur as subterms of possibly non-Boolean terms.
Example:
% Boolean constants a, b: BOOLEAN; % REAL constants x,y: REAL; % Boolean-valued function, can be used as a predicate symbol p: REAL -> BOOLEAN; ASSERT a => p(x - y); % Real-valued function with Boolean argument f: BOOLEAN -> REAL; % The argument of f can be a formula ... ASSERT f(a OR b) > 0.3 OR p(x); % ... even a quantified one ASSERT y = f(FORALL (r: REAL): r < r + 1);
The REAL Type
The type is interpreted as the set of real numbers.
Note that these are the (infinite precision) mathematical reals, not the floating point numbers. Support for floating point types is planned for future versions.
x, y : REAL; QUERY (( x <= y ) AND ( y <= x )) => ( x = y );
The INT Type
The type is interpreted as the set of integer numbers
and is considered a subtype of .
The latter means in particular that it is possible to mix integer and real terms
in expressions without the need of an explicit upcasting operator.
Note that these are the (infinite precision) mathematical integers, not the finite precision machine integers used in most programming languages. The latter are modeled by bit vector types.
x, y : INT; QUERY ((2 * x + 4 * y <= 1) AND ( y >= x)) => (x <= 0); z : REAL; QUERY (2 * x + z <= 3.5) AND (z >= 1);
Bit Vector Types
For every positive integer 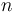 , the type is interpreted as the set of all bit vectors of size .
A rich set of bit vector operators is supported.
, the type is interpreted as the set of all bit vectors of size .
A rich set of bit vector operators is supported.
User-defined Basic Types
Users can define new basic types (often referred to as uninterpreted types in the SMT literature). Each such type is interpreted as a set of unspecified cardinality but disjoint from any other type. User-defined basic types are created by declarations like the following:
% User declarations of basic types: MyBrandNewType: TYPE; Apples, Oranges: TYPE;
Structured Types
CVC4's structured types are divided into the following families.
Array Types
Array types are created by the mixfix type constructors 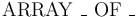 whose arguments can be instantiated by any value type.
whose arguments can be instantiated by any value type.
I : TYPE; %% Array types: % Arrays with indices from I and values from REAL Array1: TYPE = ARRAY I OF REAL; % Arrays with integer indices and array values Array2: TYPE = ARRAY INT OF (ARRAY INT OF REAL); % Arrays with integer pair indices and integer values IntMatrix: TYPE = ARRAY [INT, INT] OF INT;
An array type of the form 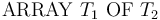 is interpreted
as the set of all total maps from
is interpreted
as the set of all total maps from 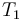 to
to 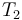 .
The main difference with the function type
.
The main difference with the function type 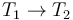 is that arrays,
contrary to functions, are first-class objects of the language, that is, values of an array
type can be arguments or results of functions.
Furthermore, array types come equipped with an update operation.
is that arrays,
contrary to functions, are first-class objects of the language, that is, values of an array
type can be arguments or results of functions.
Furthermore, array types come equipped with an update operation.
Tuple Types
Tuple types are created by the mixfix type constructors
![\begin{array}{l} [\ \_\ ] \\[1ex] [\ \_\ ,\ \_\ ] \\[1ex] [\ \_\ ,\ \_\ \ ,\ \_\ ] \\[1ex] \ldots \end{array}](/w/images/math/3/6/3/363b37d8100a693eb31d36831485ad6d.png)
whose arguments can be instantiated by any value type.
IntArray: TYPE = ARRAY INT OF INT; % Tuple type declarations EmptyTupleType: TYPE = []; % this is a unit type RealPair: TYPE = [REAL, REAL]; MyTuple: TYPE = [ REAL, IntArray, [INT, INT] ];
A tuple type of the form ![[T_1, \ldots, T_n]](/w/images/math/c/9/f/c9fba5c5df4d2385d01d4063e9ee86a9.png) is interpreted
as the Cartesian product
is interpreted
as the Cartesian product  .
.
Note that while the types 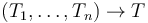 and
and
![[T_1 \times \cdots \times T_n] \to T](/w/images/math/5/e/7/5e7d9275ad22c39ef5ea9d44c1a45190.png) are semantically equivalent,
they are operationally different in CVC4.
The first is the type of functions that take arguments
of respective type ,
are semantically equivalent,
they are operationally different in CVC4.
The first is the type of functions that take arguments
of respective type ,  ,
, 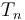 ,
while the second is the type of functions that take one argument of an -tuple type.
,
while the second is the type of functions that take one argument of an -tuple type.
Record Types
Similar to, but more general than tuple types, record types are created by type constructors of the form
![[\#\ l_1: \_\ ,\ \ldots\ ,\ l_n: \_\ \#]](/w/images/math/5/1/c/51c734d9fa14b2fbe03f3eedaec9c036.png)
where 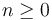 ,
,  are field labels,
and the arguments can be instantiated with any first-order types.
are field labels,
and the arguments can be instantiated with any first-order types.
MyType: TYPE; % Record declaration RecordType: TYPE = [# id: REAL, age: INT, info: MyType #];
The order of the fields in a record type is meaningful: permuting the field names gives a different type.
Note that record types are non-recursive.
For instance, it is not possible to declare a record type called Person containing
a field of type Person.
Recursive types are provided in CVC4 by the more general inductive data types.
(As a matter of fact, both record and tuple types are implemented internally as inductive data types.)
Inductive Data Types
Inductive data types in CVC4 are similar to inductive data types of functional languages. They can be parametric or not.
Non-Parametric Data Types
Non-parametric data types are created by declarations of the form
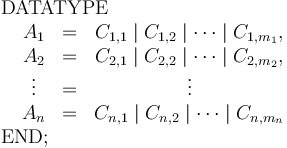
where
each 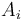 is a type name and
each
is a type name and
each 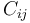 is either a constant symbol or an expression of the form
is either a constant symbol or an expression of the form
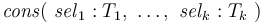
where  are any first-order types, including any .
Such declarations define the data types
are any first-order types, including any .
Such declarations define the data types  .
For each data type they introduce:
.
For each data type they introduce:
- constructor symbols
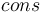 of type
of type 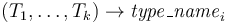 ,
, - selector symbols
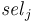 of type
of type 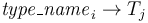 , and
, and - tester symbols
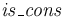 of type
of type 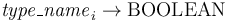 .
.
Note that permitting more than one data type to be defined in the same declarations allows the definition of mutually recursive types.
% simple enumeration type
% implicitly defined are the testers: is_red, is_yellow and is_blue
% (similarly for the other data types)
DATATYPE
PrimaryColor = red | yellow | blue
END;
% infinite set of pairwise distinct values ..., v(-1), v(0), v(1), ...
DATATYPE
Id = v (id: INT)
END;
% ML-style integer lists
DATATYPE
IntList = nil | ins (head: INT, tail: IntList)
END;
% AST for lamba calculus
DATATYPE
Term = var (index: INT)
| apply (arg_1: Term, arg_2: Term)
| lambda (arg: INT, body: Term)
END;
% Trees
DATATYPE
Tree = tree (value: REAL, children: TreeList),
TreeList = nil_tl
| ins_tl (first_t1: Tree, rest_t1: TreeList)
END;
Constructor, selector and tester symbols defined for a data type have global scope. So, for example, it is not possible for two different data types to use the same name for a constructor.
An inductive data type is interpreted as a term algebra constructed by the constructor symbols
over some sets of generators.
For example, the type IntList defined above is interpreted as the set
of all terms constructed with nil and ins over the integers.
Parametric Data Types
Parametric data types are infinite families of (non-parametric) data types with each family parametrized by one or more type variables. They are created by declarations of the form
![\begin{array}{l}
\mathrm{DATATYPE} \\
\begin{array}{ccc}
\ \ A_1[X_{1,1}, \ldots, X_{1,p_1}] & = & C_{1,1} \mid C_{1,2} \mid \cdots \mid C_{1,m_1}, \\
\ \ A_2[X_{2,1}, \ldots, X_{2,p_2}] & = & C_{2,1} \mid C_{2,2} \mid \cdots \mid C_{2,m_2}, \\
\ \ \vdots & = & \vdots \\
\ \ A_n[X_{n,1}, \ldots, X_{n,p_n}] & = & C_{n,1} \mid C_{n,2} \mid \cdots \mid C_{n,m_n} \\
\end{array}
\\
\mathrm{END};
\end{array}](/w/images/math/9/c/6/9c68f4a5f51af78749ecfcaa2a084b37.png)
where
each is a type name parametrized by the type variables  and
each is either a constant symbol or an expression of the form
and
each is either a constant symbol or an expression of the form
where are any first-order types,
possibly parametrized by  , including any .
, including any .
% Parametric pairs DATATYPE Pair[X, Y] = pair (first: X, second: Y) END; % Parametric lists DATATYPE List[X] = nil | cons (head: X, tail: List[X]) END; % Parametric trees using the list type above DATATYPE Tree[X] = node (value: X, children: List[Tree[X]]), END;
The declarations above define infinitely many types of the form
Pair[S,T], List[T] and Tree[T] where S and T are first-order types.
Note that the identifier List above, for example, by itself does not denote a type.
In contrast, the terms List[Real], List[List[Real]], List[Tree[INT]],
and so on do.
Restriction to Inductive Types
By adopting a term algebra semantics, CVC4 allows only inductive data types, that is, data types whose values are essentially (labeled, ordered) finite trees. Infinite structures such as streams or even finite but cyclic ones such as circular lists are then excluded. For instance, none of the following declarations define inductive data types, and are rejected by CVC4:
DATATYPE
IntStream = s (first:INT, rest: IntStream)
END;
DATATYPE
RationalTree = node1 (child: RationalTree)
| node2 (left_child: RationalTree, right_child:RationalTree)
END;
DATATYPE
T1 = c1 (s1: T2),
T2 = c2 (s2: T1)
END;
In concrete, a declaration of 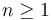 datatypes
datatypes  will be rejected if for any one of the types , it is impossible to build a finite term of that type using only the constructors of and free constants of type other than .
will be rejected if for any one of the types , it is impossible to build a finite term of that type using only the constructors of and free constants of type other than .
Inductive data types are the only types where the user also chooses names for the built-in operations to:
- construct a value of the type (with the constructors),
- extract components from a value (with the selectors), or
- check if a value was constructed with a certain constructor or not (with the testers).
For all the other types, CVC4 provides predefined names for the built-in operations on the type.
Function Types
Function ( ) types are created by the mixfix type constructors
) types are created by the mixfix type constructors
![\begin{array}{l}
\_ \to \_ \\[1ex] (\ \_\ ,\ \_\ ) \to \_
\\[1ex] (\ \_\ ,\ \_\ ,\ \_\ ) \to \_
\\[1ex] \ldots
\end{array}](/w/images/math/f/0/5/f05367bbd89f32c4ca754b620c82f158.png)
whose arguments can be instantiated by any first-order type.
% Function type declarations UnaryFunType: TYPE = INT -> REAL; BinaryFunType: TYPE = (REAL, REAL) -> ARRAY REAL OF REAL; TernaryFunType: TYPE = (REAL, BITVECTOR(4), INT) -> BOOLEAN;
A function type of the form with is interpreted as the set of all total functions from the Cartesian product to 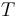 .
.
The example above also shows how to introduce type names.
A name like UnaryFunType above is just an abbreviation for the type 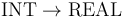 and can be used interchangeably with it.
and can be used interchangeably with it.
In general, any type defined by a type expression E can be given a name with the declaration:
name : TYPE = E;
Type Checking
In CVC4, formulas and terms are statically typed at the level of types
(as opposed to subtypes) according to the usual rules of first-order many-sorted logic,
with the main difference that formulas are just terms of type 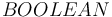 :
:
- each variable has one associated first-order type,
- each constant symbol has one or more associated first-order types,
- each function symbol has one or more associated function types,
- the type of a term consisting just of a variable is the type associated to that variable,
- the type of a term consisting just of a constant symbol is the type associated to that constant symbol,
- the term obtained by applying a function symbol
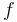 to the terms
to the terms  is if has type and each
is if has type and each 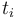 has type
has type 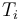 .
.
Attempting to enter an ill-typed term will result in an error.
Another significant difference with standard many-sorted logic is that
some built-in symbols are parametrically polymorphic.
For instance, the function symbol for extracting the element of any array has
type 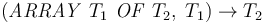 for all first-order types
for all first-order types 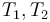 .
.
Type Ascription
By the type inference rules above some terms might have more than one type.
This can happen with terms built with polymorphic data type constructors
that have more than one return type for the same input type.
In that case, a type ascription operator (::) must be applied
to the constructor to specify the intended return type.
DATATYPE [X] List[X] = nil | cons (head: X, tail: List[X]) END; ASSERT y = cons(1, nil::List[REAL]); DATATYPE [X, Y] Union[X, Y] = left(val_l: X) | right(val_r: Y) END; ASSERT y = left::Union[BOOLEAN, REAL](TRUE);
The constant symbol 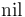 declared above has infinitely many types
(
declared above has infinitely many types
(![\mathrm{List}[\mathrm{REAL}]](/w/images/math/2/d/1/2d16f38725189013d5de469f1d61410c.png) ,
, ![\mathrm{List}[\mathrm{BOOLEAN}]](/w/images/math/9/4/b/94b40c9bef740d73ce1476fe36e20642.png) ,
,
![\mathrm{List}[[\mathrm{REAL}, \mathrm{REAL}]]](/w/images/math/0/a/d/0ad9ef6e5b4f5c64470741488fead040.png) ,
,
![\mathrm{List}[\mathrm{List}[\mathrm{REAL}]]](/w/images/math/5/b/3/5b3b5042c240d165d3a6a70524bb99c9.png) , ...)
CVC4's type checker requires the user to indicate explicitly the type
of each occurrence of
, ...)
CVC4's type checker requires the user to indicate explicitly the type
of each occurrence of nil in a term.
Similarly,
the injection operator left has infinitely many return types
for the same input type, for instance:
![\mathrm{BOOLEAN} \to \mathrm{Union}[\mathrm{BOOLEAN}, \mathrm{REAL}]](/w/images/math/f/f/8/ff835defb13072f3fb1232c0064fe7e7.png) ,
,
![\mathrm{BOOLEAN} \to \mathrm{Union}[\mathrm{BOOLEAN}, [\mathrm{REAL}, \mathrm{REAL}]]](/w/images/math/e/d/7/ed7d8d26e627cc89cb7c03830b717d11.png) ,
,
![\mathrm{BOOLEAN} \to \mathrm{Union}[\mathrm{BOOLEAN}, \mathrm{List}[\mathrm{REAL}]]](/w/images/math/f/8/2/f8280251cb3d7261fdcba998a4ffb6cd.png) ,
and so on.
Applications of
,
and so on.
Applications of left need to specify the intended returned typed, as shown above.
Terms and Formulas
In addition to type expressions, CVC4 has expressions for terms and for formulas
(i.e., terms of type ).
By and large, these are standard first-order terms built out of typed variables,
predefined theory-specific operators, free (i.e., user-defined) function symbols,
and quantifiers.
Extensions include an if-then-else operator, lambda abstractions, and local symbol
declarations, as illustrated below.
Note that these extensions still keep CVC4's language first-order.
In particular, lambda abstractions are restricted to take and return only terms of
a first-order type.
Similarly, variables can only be of a first-order type.
A number of built-in function symbols (for instance, the arithmetic ones) are used as infix operators. All user-defined symbols are used as prefix ones.
User-defined, i.e., free, function symbols include constant symbols and
predicate symbols, respectively nullary function symbols and function symbols
with a return type.
These symbols are introduced with global declarations of the form
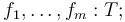 where
where 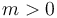 ,
, 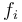 are the names of the symbols and
is their type:
are the names of the symbols and
is their type:
% integer constants a, b, c: INT; % real constants x, y, z: REAL; % unary function f1: REAL -> REAL; % binary function f2: (REAL, INT) -> REAL; % unary function with a tuple argument f3: [INT, REAL] -> BOOLEAN; % binary predicate p: (INT, REAL) -> BOOLEAN; % Propositional "variables" P, Q: BOOLEAN;
Like type declarations, function symbol declarations like the above have global scope and must be unique. In other words, it is not possible to declare a function symbol globally more than once in the same lexical scope. This entails among other things that globally-defined free symbols cannot be overloaded with different types and that theory symbols cannot be redeclared globally as free symbols.
Global symbol definitions
As with types, a function symbol can be defined as the name of another term
of the corresponding type.
With constant symbols, this is done with a declaration of the form 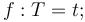 :
:
c: INT; i: INT = 5 + 3*c; % i is effectively a shorthand for 5 + 3*c j: REAL = 3/4; t: [REAL, INT] = (2/3, -4); r: [# key: INT, value: REAL #] = (# key := 4, value := (c + 1)/2 #); f: BOOLEAN = FORALL (x:INT): x <= 0 OR x > c ;
A restriction on constants of type 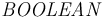 is that their value
can only be a closed formula, that is, a formula with no free variables.
is that their value
can only be a closed formula, that is, a formula with no free variables.
A term and its name can be used interchangeably in later expressions. Named terms are often useful for shared subterms (terms used several times in different places) since their use can make the input exponentially more concise. Named terms are processed very efficiently by CVC4. It is much more efficient to associate a complex term with a name directly rather than to declare a constant and later assert that it is equal to the same term. This point is explained in more detail later in section Commands.
More generally, in CVC4 one can associate a term to function symbols of any arity. For non-constant function symbols this is done with a declaration of the form
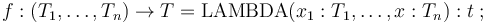
where 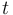 is any term of type with free variables
in
is any term of type with free variables
in  .
The lambda binder has the usual semantics and conforms to the usual lexical scoping rules:
within the term the declaration of the symbols
.
The lambda binder has the usual semantics and conforms to the usual lexical scoping rules:
within the term the declaration of the symbols  as local variables of respective type hides any previous
declarations of those symbols that are in scope.
as local variables of respective type hides any previous
declarations of those symbols that are in scope.
As a general shorthand, when 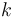 consecutive types
consecutive types
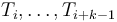 in the lambda expression
in the lambda expression
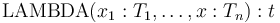 are identical, the syntax
are identical, the syntax
 can also be used.
can also be used.
% Global declaration of x as a unary function symbol x: REAL -> REAL; % Local declarations of x as variable (hiding the global one) f: REAL -> REAL = LAMBDA (x: REAL): 2*x + 3; p: (INT, INT) -> BOOLEAN = LAMBDA (x,i: INT): i*x - 1 > 0; g: (REAL, INT) -> [REAL, INT] = LAMBDA (x: REAL, i:INT): (x + 1, i - 3);
Note that lambda definitions are not recursive:
the symbol being defined cannot occur in the body of the lambda term.
They should be understood as macros.
For instance, any occurrence of the term 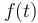 where is as defined above will be treated
as if it was the term
where is as defined above will be treated
as if it was the term 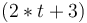 .
.
Local symbol definitions
Constant and function symbols can also be declared locally anywhere within a term by means of a let binder. This is done with a declaration of the form
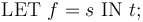
where is a term with no free variables, possibly a lambda term.
Let binders can be nested arbitrarily and follow the usual lexical scoping rules.
The following general form
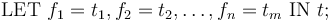
can used as a shorthand for
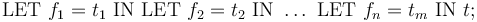
t: REAL =
LET x1 = 42,
g = LAMBDA(x:INT): x + 1,
x2 = 2*x1 + 7/2
IN
(LET x3 = g(x1) IN x3 + x2) / x1;
Note that the same symbol = is used, unambiguously, in the syntax of global declarations, let declarations, and as a predicate symbol.
Note:
A 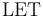 term with a multiple symbols defines them sequentially.
A parallel version of the construct will be introduced in a later version.
term with a multiple symbols defines them sequentially.
A parallel version of the construct will be introduced in a later version.
Built-in theories and their symbols
In addition to user-defined symbols, CVC4 terms can use a number of predefined symbols:
the logical symbols, such as  ,
, 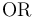 , etc.,
as well as theory symbols, function symbols belonging to one of the built-in theories.
They are described next, with the theory symbols grouped by theory.
, etc.,
as well as theory symbols, function symbols belonging to one of the built-in theories.
They are described next, with the theory symbols grouped by theory.
Logical Symbols
The logical symbols in CVC4's language include
the equality and disequality predicate symbols, respectively written as = and /=,
the multiarity disequality symbol 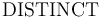 ,
together with the logical constants
,
together with the logical constants 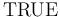 ,
, 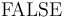 ,
the connectives
,
the connectives 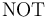 , , ,
, , , 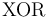 ,
,  ,
,  , and
the first-order quantifiers
, and
the first-order quantifiers 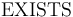 and
and 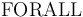 ,
all with the standard many-sorted logic semantics.
,
all with the standard many-sorted logic semantics.
The binary connectives have infix syntax and type
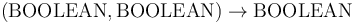 .
The symbols = and /=, which are also infix, are instead parametrically polymorphic,
having type
.
The symbols = and /=, which are also infix, are instead parametrically polymorphic,
having type 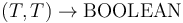 for every first-order type .
They are interpreted respectively as the identity relation and its complement.
for every first-order type .
They are interpreted respectively as the identity relation and its complement.
The DISTINCT symbol is both overloaded and polymorphic.
It has type 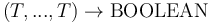 for every sequence
for every sequence 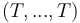 of length
and first-order type .
For each , it is interpreted as the relation
that holds exactly for tuples of pairwise distinct elements.
of length
and first-order type .
For each , it is interpreted as the relation
that holds exactly for tuples of pairwise distinct elements.
The syntax for quantifiers is similar to that of the lambda binder.
Here is an example of a formula built just of these logical symbols and variables:
A, B: TYPE;
q: BOOLEAN = FORALL (x,y: A, i,j,k: B):
i = j AND i /= k => EXISTS (z: A): x /= z OR z /= y;
Binding and scoping of quantified variables follows the same rules as in let expressions. In particular, a quantifier will shadow in its scope any constant and function symbols with the same name as one of the variables it quantifies:
A: TYPE; i, j: INT; % The first occurrence of i and of j in f are constant symbols, % the others are variables. f: BOOLEAN = i = j AND FORALL (i,j: A): i = j OR i /= j;
Optionally, it is also possible to specify instantiation patterns
for quantified variables.
The general syntax for a quantified formula 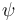 with patterns is
with patterns is
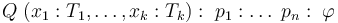
where , 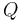 is
either or ,
is
either or ,
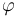 is a term of type ,
and each of the
is a term of type ,
and each of the 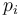 's,
a pattern for the quantifier
's,
a pattern for the quantifier 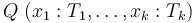 , has the form
, has the form
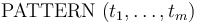
where and  are
arbitrary binder-free terms (no lets, no quantifiers).
Those terms can contain (free) variables, typically, but not exclusively,
drawn from
are
arbitrary binder-free terms (no lets, no quantifiers).
Those terms can contain (free) variables, typically, but not exclusively,
drawn from  .
(Additional variables can occur if occurs in a bigger formula
binding those variables.)
.
(Additional variables can occur if occurs in a bigger formula
binding those variables.)
A: TYPE;
b, c: A;
p, q: A -> BOOLEAN;
r: (A, A) -> BOOLEAN;
ASSERT FORALL (x0, x1, x2: A):
PATTERN (r(x0, x1), r(x1, x2)):
(r(x0, x1) AND r(x1, x2)) => r(x0, x2) ;
ASSERT FORALL (x: A):
PATTERN (r(x, b)):
PATTERN (r(x, c)):
p(x) => q(x) ;
ASSERT EXISTS (y: A):
FORALL (x: A):
PATTERN (r(x, y), p(y)):
r(x, y) => q(x) ;
Patterns have no logical meaning: adding them to a formula does not change its semantics. Their purpose is purely operational, as explained in the Instantiation Patterns section.
In addition to these constructs, CVC4 also has a general mixfix conditional operator of the form
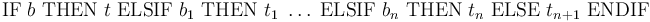
with where
 are terms of type and
are terms of type and
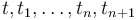 are terms of the same first-order type :
are terms of the same first-order type :
% Conditional term x, y, z, w: REAL; t: REAL = IF x > 0 THEN y ELSIF x >= 1 THEN z ELSIF x > 2 THEN w ELSE 2/3 ENDIF;
User-defined Functions and Types
The theory of user-defined functions,also know in the SMT literature as the theory Equality over Uninterpreted Functions, or EUF, is in effect a family of theories of equality parametrized by the basic types and the free symbols a user can define during a run of CVC4.
This theory has no built-in symbols (other than the logical ones). Its types consist of all and only the user-defined types. Its function symbols consist of all and only the user-defined free symbols.
Arithmetic
The real arithmetic theory has two types:
and 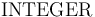 with the latter a subtype of the first.
Its built-in symbols for the usual arithmetic constants
and operators over the type , each with the expected type:
all numerals 0, 1, ..., as well as - (both unary and binary), +, *, /, <, >, <=, >=.
Application of the binary symbols are in infix form.
Note that + is only binary, and so an expression such as +4 is ill-formed.
with the latter a subtype of the first.
Its built-in symbols for the usual arithmetic constants
and operators over the type , each with the expected type:
all numerals 0, 1, ..., as well as - (both unary and binary), +, *, /, <, >, <=, >=.
Application of the binary symbols are in infix form.
Note that + is only binary, and so an expression such as +4 is ill-formed.
Rational values can be expressed in decimal or fractional format, e.g., 0.1, 23.243241, 1/2, 3/4, and so on. A leading 0 is mandatory for decimal numbers smaller than one (e.g., the syntax .3 cannot be used as a shorthand for 0.3). However, a trailing 0 is not required for decimals that are whole numbers (e.g., 3. is allowed as a shorthand for 3.0). The size of the numerals used in the representation of natural and rational numbers is unbounded; more accurately, bounded only by the amount of available memory.
Bit vectors
Arrays
The theory of arrays is a parametric theory of (total) unary maps. It comes equipped with mixfix polymorphic selection and update operators, respectively
![\_[\_]](/w/images/math/4/a/2/4a2e18f55a77d1837ef34ba945085e81.png) and
and ![\_\ \mathrm{WITH}\ [\_]\ := \_](/w/images/math/b/a/1/ba1c75187dd461efe773b6e869cd0ba7.png) .
.
The semantics of these operators is the expected one:
for all first-order types and ,
if 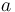 is of type
is of type 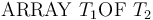 ,
,
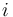 is of type , and
is of type , and
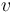 is of type ,
is of type ,
-
![a[i]](/w/images/math/5/9/5/595711c58954cfc2eb727cba561e3512.png) denotes the value that associates to index ,
denotes the value that associates to index , -
![a\ \mathrm{WITH}\ [i]\ := v](/w/images/math/d/7/f/d7f9d1a4db09b9e1cf83ec5805394e65.png) denotes a map that associates to index and is otherwise identical to .
denotes a map that associates to index and is otherwise identical to .
Sequential updates can be chained with the shorthand syntax
![\_\ \mathrm{WITH}\ [\_]\ := \_, \ldots, [\_]\ := \_](/w/images/math/9/6/0/9607705d830a35d96751ffcd1d491fd5.png) .
.
A: TYPE = ARRAY INT OF REAL; a: A; i: INT = 4; % selection: elem: REAL = a[i]; % update a1: A = a WITH [10] := 1/2; % sequential update % (syntactic sugar for (a WITH [10] := 2/3) WITH [42] := 3/2) a2: A = a WITH [10] := 2/3, [42] := 3/2;
Since arrays are just maps, equality between them is extensional, that is, for two arrays of the same type to be different they have to map at least one index to differ values.
Data types
The theory of inductive data types is in fact a family of theories parametrized by a data type declaration specifying constructors and selectors for one or more user-defined data types.
No built-in operators other than equality and disequality are provided for this family in the native language. Each user-provided data type declaration, however, generates constructor, selector and tester operators as described in the Inductive Data Types section.
Tuples and Records
Semantically both records and tuples can be seen as special instances
of inductive data types.
CVC4 implements them internally indeed as data types.
In essence, a record type ![[\#\ l_0:T_0, \ldots, l_n:T_n\ \#]](/w/images/math/d/3/2/d32254e7016873239bd2e36120e7e544.png) is encoded as a data type of the form
is encoded as a data type of the form
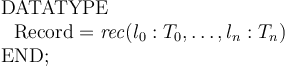
Tuples of length are in turn special cases of records whose field names are
the numerals from 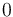 to
to 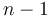 .
.
Externally, tuples and records have their own syntax for constructor and selector operators.
- Records of type have the associated record constructor
 whose arguments must be terms of type
whose arguments must be terms of type  , respectively.
, respectively. - Tuples of type
![[\ T_0, \ldots, T_n\ ]](/w/images/math/5/4/7/547c8eb765415544e64bc4c77519e72e.png) have the associated tuple constructor
have the associated tuple constructor  whose arguments must be terms of type , respectively. Note that the empty tuple can be created with
whose arguments must be terms of type , respectively. Note that the empty tuple can be created with 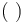 ; however, a single-element tuple cannot be directly created, as
; however, a single-element tuple cannot be directly created, as  is interpreted as a parenthesized (non-tuple) expression.
is interpreted as a parenthesized (non-tuple) expression.
The selector operators on records and tuples follows a dot notation syntax.
% Record construction and field selection Item: TYPE = [# key: INT, weight: REAL #]; x: Item = (# key := 23, weight := 43/10 #); k: INT = x.key; v: REAL = x.weight; % Tuple construction and projection y: [REAL, INT, REAL] = ( 4/5, 9, 11/9 ); first_elem: REAL = y.0; third_elem: REAL = y.2;
Differently from data types, records and tuples are also provided with built-in update operators similar in syntax and semantics to the update operator for arrays.
More precisely, for each record type and
each 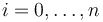 , CVC4 provides the operator
, CVC4 provides the operator
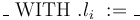
The operator maps a record 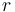 of that type and a value
of type to the record that stores in field
of that type and a value
of type to the record that stores in field 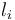 and is otherwise identical to .
Analogously, for each tuple type
and is otherwise identical to .
Analogously, for each tuple type ![[T_0, \ldots, T_n]](/w/images/math/e/7/c/e7c044c5044f03caae7f99e5a699a069.png) and
each , CVC4 provides the operator
and
each , CVC4 provides the operator
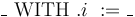
with similar semantics.
% Record updates Item: TYPE = [# key: INT, weight: REAL #]; x: Item = (# key := 23, weight := 43/10 #); x1: Item = x WITH .weight := 48; % Tuple updates Tup: TYPE = [REAL,INT,REAL]; y: Tup = ( 4/5, 9, 11/9 ); y1: Tup = y WITH .1 := 3; Updates to a nested component can be combined in a single WITH operator: Cache: TYPE = ARRAY [0..100] OF [# addr: INT, data: REAL #]; State: TYPE = [# pc: INT, cache: Cache #]; s0: State; s1: State = s0 WITH .cache[10].data := 2/3;
Note that, differently from updates on arrays, tuple and record updates are
just additional syntactic sugar.
For instance, the record x1 and tuple y1 defined above
could have been equivalently defined as follows:
% Record updates Item: TYPE = [# key: INT, weight: REAL #]; x: Item = (# key := 23, weight := 43/10 #); x1: Item = (# key := x.key, weight := 48 #); % Tuple updates Tup: TYPE = [REAL,INT,REAL]; y: Tup = ( 4/5, 9, 11/9 ); y1: Tup = ( y.0, 3, y.1 );
Commands
In addition to declarations of types and function symbols, the CVC4 native language contains the following commands:
-
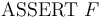 -- Add the formula
-- Add the formula 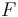 to the current logical context
to the current logical context 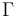 .
. -
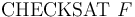 -- Check if the formula is satisfiable in the current logical context (
-- Check if the formula is satisfiable in the current logical context (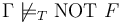 ).
). -
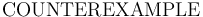 -- After an invalid
-- After an invalid 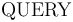 or satisfiable
or satisfiable 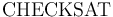 , print the context that is a witness for invalidity/satisfiability.
, print the context that is a witness for invalidity/satisfiability. -
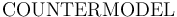 -- After an invalid or satisfiable , print a model that makes the formula invalid/satisfiable. The model is provided in terms of concrete values for each free symbol.
-- After an invalid or satisfiable , print a model that makes the formula invalid/satisfiable. The model is provided in terms of concrete values for each free symbol. -
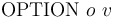 -- Set the command-line option flag
-- Set the command-line option flag 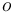 to value . The argument is provide as a string literal enclosed in double-quotes and as an integer value.
to value . The argument is provide as a string literal enclosed in double-quotes and as an integer value. -
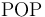 -- Restore the system to the state it was in right before the most recent call to
-- Restore the system to the state it was in right before the most recent call to 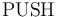 .
. -
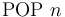 -- Equivalent to repeated times.
-- Equivalent to repeated times. - -- Save (checkpoint) the current state of the system.
-
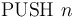 -- Equivalent to repeated times.
-- Equivalent to repeated times. -
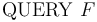 -- Check if the formula is valid in the current logical context (
-- Check if the formula is valid in the current logical context (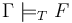 ).
). -
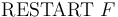 -- After an invalid or satisfiable , repeat the check but with the additional assumption in the context.
-- After an invalid or satisfiable , repeat the check but with the additional assumption in the context. -
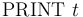 -- Parse and print back the term .
-- Parse and print back the term . -
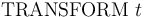 -- Simplify the term and print the result.
-- Simplify the term and print the result. -
 -- Print all the formulas in the current logical context .
-- Print all the formulas in the current logical context .
The remaining commands take a single argument, given as a string literal enclosed in double-quotes.
-
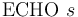 -- Print string
-- Print string 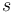
-
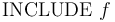 -- Read commands from file .
-- Read commands from file . -
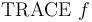 -- Turn on tracing for the debug flag .
-- Turn on tracing for the debug flag . -
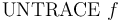 -- Turn off tracing for the debug flag .
-- Turn off tracing for the debug flag .
The following CVC3 commands are currently unsupported in CVC4.
Here, we explain some of the above commands in more detail.
QUERY
The command invokes the core functionality of CVC4 to check
the validity of the formula with respect to the assertions made thus far,
which constitute the context .
The argument must be well typed term of type ,
as described in Terms and Formulas.
The execution of this command always terminates and produces one of three possible answers:
valid, invalid, and unknown.
- A
validanswer indicates that. After a query returning such an answer, the logical context is exactly as it was before the query. - An
invalidanswer indicates that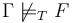 , that is, there is a model of the background theory that satisfies
, that is, there is a model of the background theory that satisfies 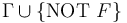 . When returns
. When returns invalid, the logical context is augmented with a set  of ground (i.e., variable-free) literals such that
of ground (i.e., variable-free) literals such that 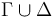 is satisfiable in , but
is satisfiable in , but 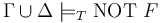 . In fact, in this case propositionally entails
. In fact, in this case propositionally entails 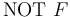 , in the sense that, every truth assignment to the literals of that satisfies falsifies . We call the new context a counterexample for .
, in the sense that, every truth assignment to the literals of that satisfies falsifies . We call the new context a counterexample for . - An
unknownanswer is similar to aninvalidanswer in that additional literals are added to the context which propositionally entail. The difference in this case is that CVC4 cannot guarantee that is actually satisfiable in .
CVC4 may report unknown when the context or the query contains
non-linear arithmetic terms or quantifiers.
In all other cases, it is expected to be sound and complete,
i.e., to report Valid if
and Invalid otherwise.
After an invalid (resp. unknown) answer,
counterexamples (resp. possible counterexamples) can be obtained with
a , ,
or command.
Since the command may modify
the current context, if one needs to check several formulas in a row
in the same context, it is a good idea to surround every
query by a and invocation
in order to preserve the context:
PUSH; QUERY <formula>; POP;
CHECKSAT
The command behaves identically
to 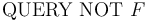 .
.
COUNTERMODEL
[More]
COUNTEREXAMPLE
[More]
PUSH and POP
CVC4's context can be understood as being stratified in assertion levels which are added and removed in a LIFO fashion. The system starts at assertion level 0 and every execution of the PUSH command creates a new assertion level after the current one. Each formula added to the context either by the user, via an ASSERT command, or internally by the system is added to the most recent assertion level. Executing POP n removes from the context the most recent n assertion levels and all the formulas in them. Note that formulas at assertion level 0 cannot be retracted.
Note: Symbol declarations are always added at assertion level zero. So they are not affected by POP commands.
Instantiation Patterns
CVC4 processes each universally quantified formula in the current context by adding instances of the formula obtained by replacing its universal variables with ground terms. Patterns restrict the choice of ground terms for the quantified variables, with the goal of controlling the potential explosion of ground instances. In essence, adding patterns to a formula is a way for the user to tell CVC4 to focus only on certain instances which, in the user's opinion, will be most helpful during a proof.
In more detail, patterns have the following effect on formulas that are found
in the logical context or get added to it later while CVC4 is trying to prove
the validity of some formula .
If a formula in the current context starts with an existential quantifier, CVC4 Skolemizes it, that is, replaces it in the context with the formula obtained by substituting the existentially quantified variables by fresh constants and dropping the quantifier. Any patterns for the existential quantifier are simply ignored.
If a formula starts with a universal quantifier
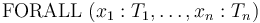 ,
CVC4 adds to the context a number of instances of the formula,
with the goal of using them to prove the query valid.
An instance is obtained by replacing each
,
CVC4 adds to the context a number of instances of the formula,
with the goal of using them to prove the query valid.
An instance is obtained by replacing each 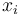 with a ground term
of the same type occurring in one of the formulas in the context,
and dropping the universal quantifier.
If occurs in a pattern
for the quantifier,
it will be instantiated only with terms obtained by simultaneously matching
all the terms in the pattern against ground terms in the current context
.
with a ground term
of the same type occurring in one of the formulas in the context,
and dropping the universal quantifier.
If occurs in a pattern
for the quantifier,
it will be instantiated only with terms obtained by simultaneously matching
all the terms in the pattern against ground terms in the current context
.
Specifically, the matching process produces one or more substitutions
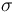 for the variables in
for the variables in  which satisfy the following invariant:
for each
which satisfy the following invariant:
for each 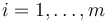 ,
, 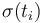 is
a ground term and there is a ground term
is
a ground term and there is a ground term 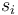 in
such that
in
such that 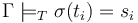 .
The variables of
.
The variables of  that occur
in the pattern are instantiated only with those substitutions
(while any remaining variables are instantiated arbitrarily).
that occur
in the pattern are instantiated only with those substitutions
(while any remaining variables are instantiated arbitrarily).
The Skolemized version or the added instances of a context formula may themselves start with a quantifier. The same instantiation process is applied to them too, recursively.
Note that the matching mechanism is not limited to syntactic matching
but is modulo the equations asserted in the context.
Because of decidability and/or efficiency limitations, the matching process
is not exhaustive.
CVC4 will typically miss some substitutions that satisfy the invariant above.
As a consequence, it might fail to prove the validity of the query formula
, which makes CVC4 incomplete for contexts containing
quantified formulas.
It should be noted though that exhaustive matching, which can be achieved
simply by not specifying any patterns, does not yield completeness anyway
since the instantiation of universal variables is still restricted
to just the ground terms in the context,
whereas in general additional ground terms might be needed.
